From ECM 1.0 to 2.0 – an intelligent way ahead….
When any technology sector becomes ‘mature’ it gets into a rut. It’s as if there is a collective question of “Why change things, aren’t we are all doing just fine?”. Even so, over the past few years, things have begun to change, and the fundamentals of how an optimal ECM system might work in the future are being reimagined.
The change in our opinion at least is due to interest in the potential of:
- Artificial Intelligence and Machine Learning
- An increased regulatory burden
- Easy access to cloud storage and distributed processing capabilities
- The need to manage, route, and control multiple sources of inputs
- Managing an overwhelming amount of unstructured data
- Increased need to process and act on data quickly
- The cumulative cost of storing large volumes of unmanaged and access data
- The move to API and service-based architectures
Together these factors provide a tipping point for new technical approaches to manage and draw value from both active and dormant files to emerge.
The fact is that first generation ECM, Document and Record Management systems were all proprietary systems built around the idea of a single repository. Or as marketers like to call it ‘a single source of truth’, one repository to rule them all.
But the world has moved on, content resides in multiple repositories, in the cloud and on premises. Our attempts at corralling everything into one place has failed. It’s time to approach the problem from a different perspective.
So, we thought it would be a good idea to provide some structure for this change in approach from ECM 1.0 to 2.0 and we came up with the following diagram:
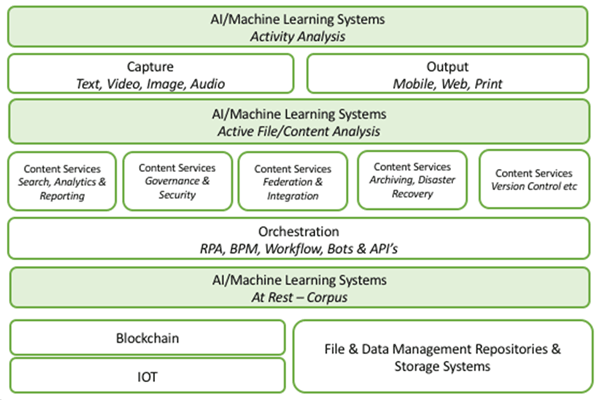
ECM 2.0
ECM 2.0 systems in the future will take a contrary position to the 1.0 systems that focused on the importance of a single repository. ECM 2.0 systems will take for granted that although some business documents and files may be closely managed in a closed repository, most will not and never will be.
2.0 also accepts that there will be multiple workflows and integration points in play within a single organisation. Again, rather than one workflow system optimised for one repository there will be multiple and (sometimes) competing automation and process systems.
In our architecture outline, 2.0 also extensively utilises traditional content analytics, AI and ML (and in some cases Deep Learning) at three layers in the stack.
Corpus Analysis
Most established firms have millions (in some cases billions) of stored historic documents sitting in legacy systems and document repositories. Few have any real insight into what is in these documents or what value (or risk) that these documents carry. Machine Learning and Deep Learning systems can be trained to analyse this corpus of data for legal discovery, the identification of risks, duplicates, and redundancy.
Active Analysis
Active files and documents in ECM 2.0 leverage machine learning to ensure that intelligent capture, document classification, summarization, and insight are applied. It’s here that we see most of the current activity in the market occurring, whether that be to improving capture efficiencies or simply applying accurate classifications to meet increasing regulatory oversight needs.
Activity Analysis
Though to date, external activity analysis has been primarily the concern of web content and There is a growing interest in analysing who engaged with the content, how they engaged with the content and when, and in the process extracting key business insights.
It’s also worth noting that Blockchain (aka distributed ledger technologies) will likely play a key role in the future of ECM. Blockchains are more than BitCoin and money laundering, they can provide an indisputable and immutable (never to be changed) audit trail of every activity and action that a piece of content or file undertakes. It’s early days but we know of many vendors and buyers of ECM technology that are actively and enthusiastically exploring its future use.
So, in summary ECM 2.0 opens up a range of possibilities to leverage the rich, yet currently unloved legacy silos of data that organisations have accumulated, whilst also extracting more value from new content and automating more activities down the line. The shift will be a major but worthwhile undertaking, and it will play out over many years.
But do not be overwhelmed, as in many cases, the first step may just be simply moving your files to cloud storage. For as the Chinese saying goes, a journey of a thousand miles begins with a single step. Carpe Diem!
Alan Pelz-Sharpe is founder of Deep Analysis LLC. If you would like a copy of our new report “Intelligent Information Management – from ECM 1.0 to 2.0” send us an email at info@deep-analysis.net.