
Fujitsu Laboratories has announced newly developed technology that offers both high speed data-processing and high-capacity storage in distributed storage systems, in order to speed up the processing of ever-increasing volumes of data.
This is in response to a growing need in such technologies as AI and machine learning for the analysis and utilization of rapidly growing volumes of data, including unstructured data, such as video and log data.
This requires storage systems that can efficiently analyse unstructured data stored in a distributed system, while providing their original storage functionality for data management as well as data processing capabilities.
Fujitsu Laboratories has now developed "Dataffinic Computing," a technology for distributed storage systems that handles data processing while also fulfilling their original storage function, in order to speed up the processing of large volumes of data.
With this technology, storage systems can process large volumes of data at high speeds, including unstructured data, enabling the efficient utilization of the ever-increasing amounts of data, in such cases as utilizing security camera video, analyzing logs from ICT systems, utilizing sensor data from cars, and analyzing genetic data.
Conventionally, data has been analyzed in processing servers, but if data could be processed in the same systems where it is stored, it is expected that would increase the speed of data analysis processing.
However, data processing requires the processing server to read the data from the storage system. As the volume of data flowing between the storage system and the processing server increases, the time required to read the data can become a bottleneck when utilizing large volumes of data.
On the other hand, data processing at high speeds becomes possible when the processing is done on the storage system without moving the data. Nonetheless, this makes it difficult to analyze unstructured data distributed across the storage system, and to maintain stable operations in the system's original storage functionality.
So. what is Dataffinic Computing?

Figure 1: Data processing with Dataffinic Computing
1. Content-aware data disposition that can process each distributed data items
In order to improve access performance, distributed storage systems do not store large amounts of data in the same place, but break the data into sizes that are easy to manage for storage. In the case of unstructured data such as videos and log data, however, individual pieces of data cannot be completely processed when the file is systematically broken down into pieces of specified size and stored separately.
It was therefore necessary to once again gather together the distributed data for processing, placing a significant load on the system. Now, by breaking down unstructured data along natural breaks in the connections within the data, this technology stores the data in a state in which the individual pieces can still be processed. In addition, information essential for processing (such as header information) is attached to each piece of data. This means that the pieces of data scattered across the distributed storage can be processed individually, maintaining the scalability of access performance and improving the system performance as a whole.

Figure 2: Storage and processing of unstructured data
2. Adaptive resource control with storage functionality and data-processing capability
In addition to the ordinary reading and writing of data, storage nodes face a variety of system loads to safely maintain data, including automatic recovery processing after an error, data redistribution processing after more storage capacity is added, and disk checking processing as part of preventive maintenance.
This technology models the types of system loads that occur in storage systems, predicting resources that will be needed in the near future. Based on this, the technology controls data processing resources and their allocation, so as not to reduce the performance of the system's storage functionality. This enables high speed data processing while still delivering stable operations for the original storage functionality.
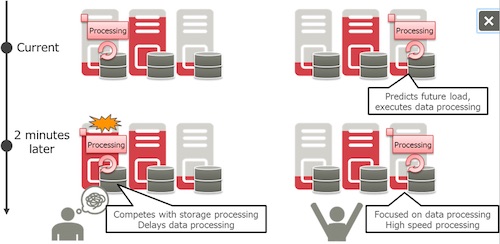
Figure 3: Technology that predicts necessary resources and controls resources for data processing
10X processing boost
Fujitsu Laboratories implemented this technology in Ceph, an open source distributed storage software solution, and evaluated its effects. Five storage nodes and five processing servers were connected with a 1 Gbps network, and data processing performance was measured when extracting objects such as people and cars from 50 GB of video data.
With the conventional method, it took 500 seconds to complete processing, but with this newly developed technology, the data processing could be done on the storage nodes, without the need to bring the data together. Moreover, the processing was completed in 50 seconds, 10 times faster than the previous method. This technology enables scalable and efficient processing of explosively increasing amounts of data.
Fujitsu Laboratories plans to continue to verify this technology for commercial applications, with Fujitsu Limited expected to launch it as a commercial product in 2019.
.